AI data engineering is not a model problem first. It is an operating model problem.
Most leaders have seen the pattern before. A dashboard is off, totals do not reconcile, or the same customer appears twice in a report. Nobody blames the chart. They trace the problem back to the data beneath it.
AI data engineering changes the consequences, not the logic. A bad dashboard is frustrating. AI data engineering built on fragmented records can route the wrong case, personalize the wrong offer, escalate the wrong issue, or give finance the wrong picture of cost and performance.
That is why enterprise AI fails fastest when teams try to automate on top of duplicate records, weak integration, unclear ownership, and inconsistent reporting. In hospitality and customer-facing operations, that shows up quickly: manual reservation follow-up stays slow, service escalation remains messy, guest personalization becomes inconsistent, and sales and support teams keep working from different versions of the truth.
The thesis is simple. Automation should be the outcome of readiness, not the starting point. If data quality is weak, data ownership is unclear, workflow orchestration is undefined, and trust controls are thin, AI data engineering will not clean up the mess. It will scale it.
This article walks through what AI-ready data pipelines actually require, which workflows are worth automating first, how to preserve human approval and personal service, when a custom assistant makes more sense than a generic chatbot, how AI data engineering connects CRM, PMS, ERP, and support systems, and how finance and technology leaders can control cost and prove ROI before a broad rollout. In practice, AI data engineering is the bridge between a promising demo and a dependable operating process. It is also what keeps AI readiness from becoming a slide deck instead of a working system.
Why AI Data Engineering Fails Fast When the Data Foundation Is Broken
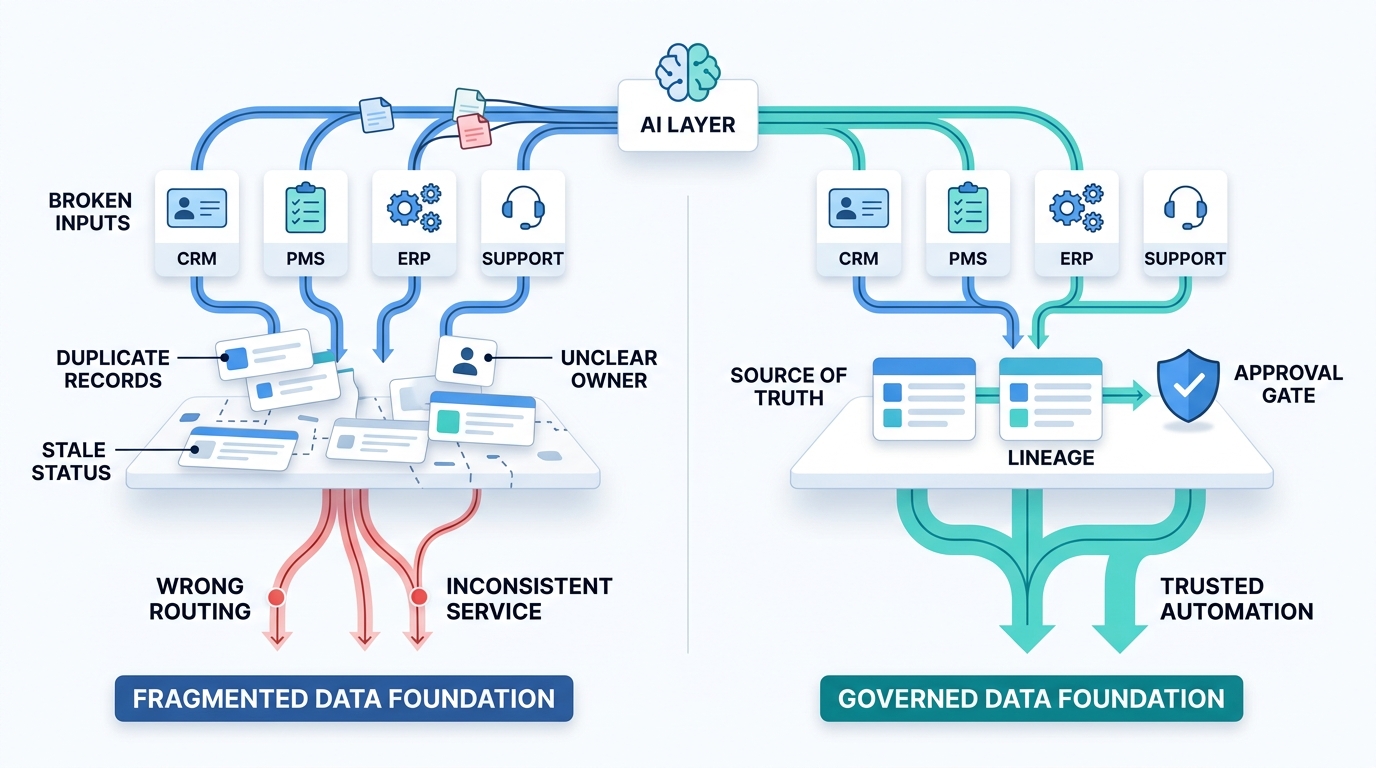
The fastest way to make AI look broken is to place it on top of broken data. That is where many enterprise efforts go off track, and it is why AI data engineering has to start with the data foundation, not the model wrapper.
AI data engineering is often asked to compensate for duplicate customer records, poor system mapping, missing ownership, and mismatched definitions across departments. Instead of creating automation, it creates faster confusion.
A hotel may see one guest in the PMS, another version of that guest in the CRM, and a third version in support history. If the profile is fragmented, the AI cannot reliably tell whether that person is a first-time booking, a loyalty member, or someone with an unresolved issue. The result is not smart service. It is inconsistent guest personalization.
The same pattern shows up in non-hospitality workflows. A service team may add AI to speed up routing, but if account status is stale, ownership is unclear, or the support taxonomy does not match what sales uses, the system simply makes the routing error happen sooner.
This is why trustworthy AI is framed as a governance and risk problem, not only a model problem, in NIST’s AI Risk Management Framework, the NIST AI RMF Playbook, the OECD AI Principles, and ISO/IEC 42001 for AI management systems. Those frameworks point to the same executive lesson: accountability, traceability, and management discipline matter if AI is going to be trusted in production. AI data engineering only works when that discipline is built into the operating model.
The goal is not perfect data everywhere. That is unrealistic. The goal is enough quality, ownership, and lineage in the workflows that matter so AI can act safely, predictably, and measurably. That is the practical standard for AI readiness, and it is the first test of AI data engineering.
What AI-Ready Data Actually Means in Enterprise Operations
AI-ready data pipelines are not just pipes that move records from one system to another. They are enterprise data pipelines designed around quality, ownership, lineage, and controlled access. In other words, AI data engineering is not finished when the integration works; it is finished when the workflow can be trusted.
In plain terms, AI readiness means you know which system is authoritative, who owns the fields that matter, how records change over time, and what should happen when the AI encounters ambiguity. Without that, AI data engineering may look complete in architecture diagrams while remaining fragile in real operations.
Data quality is really a business accountability issue
Data quality for AI is often treated like a cleanup project for the data team. In reality, it is a cross-functional operating decision. Someone has to own the definition of a guest profile, an account status, a reservation state, a loyalty tier, or a service priority.
If nobody owns those definitions, AI will act on assumptions. That is why data ownership matters as much as schema design, and why AI data engineering has to include business stewardship, not just technical mapping.
Lineage and governance decide whether the output can be trusted
If a finance leader asks, “Where did this answer come from?” or a support leader asks, “Why was this case routed here?”, your team needs a clear answer. AI data governance and lineage help create that answer. Google Cloud’s data governance guidance and Google Cloud’s documentation on data lineage explain why it matters to understand where data came from and how it changed over time. Microsoft Fabric governance documentation also emphasizes governance controls for trusted enterprise data foundations.
This matters because AI does not just read data. It combines, summarizes, and uses it to influence action. If the lineage is unclear, confidence in the outcome should be low. Strong AI data engineering makes traceability part of the design, not an afterthought.
The practical test of AI readiness
A useful starting point is to ask four questions before any automation discussion:
- Which record is the source of truth?
- Who owns the business definition behind it?
- Which systems need that context in real time or near real time?
- What happens when the record is incomplete or conflicting?
If those answers are vague, AI readiness is low, no matter how polished the demo looks.
That is the real work of AI data engineering. It is not just moving data into a platform. It is deciding which data can support action, which process can tolerate automation, and where human approval must remain in the loop.
| Workflow | Data Quality | Ownership Clarity | Integration Coverage | Human Approval Needed | Cost Risk | Automation Priority |
|---|---|---|---|---|---|---|
| Manual reservation follow-up | Medium to High if booking and guest profile are aligned | Clear if reservations lead owns outcome | CRM + PMS + support context needed | Yes for VIP, refund, or disruption cases | Medium | High |
| Manual service case routing | Medium if categories and SLAs are standardized | Clear if support ops owns routing logic | CRM + support platform + account status | Yes for edge cases | Medium | High |
| Manual loyalty follow-up | High only if consent, tier, and history are reliable | Clear if loyalty team owns offer rules | CRM + loyalty + PMS | Yes for sensitive offers | Medium | Medium to High |
| Customer-facing complaint resolution | Variable and emotionally sensitive | Often shared across teams | Broad integration required | High | High | Low for first rollout |
| Revenue or pricing recommendations | High-quality historical and operational data required | Cross-functional ownership needed | PMS + ERP + BI + market inputs | High | High | Low for first rollout |
That table is the heart of AI data engineering in practice. The question is not whether a model can perform a task. It is whether the workflow is ready to be automated safely.
Which Workflow Should Be Automated First in Hospitality and Service Operations
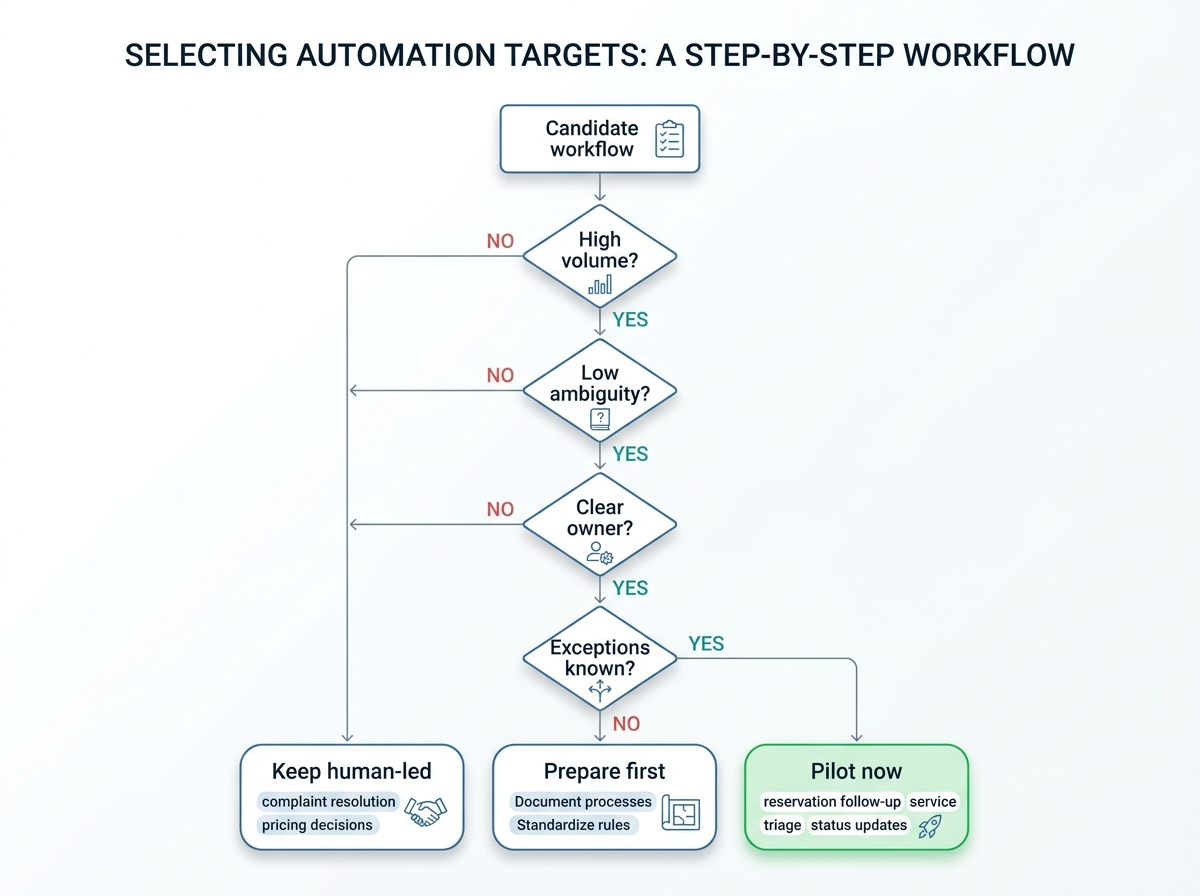
Once the data foundation is visible, the question changes. It is no longer, “What can we automate?” It becomes, “Which workflow deserves AI data engineering first?”
The first workflow should be repetitive, high-volume, bounded, and easy to measure. That usually means a workflow with low ambiguity and a clear owner: reservation follow-up, routine service triage, internal status updates, or case classification.
Start where the process is clean and the exception path is known
If you lead hospitality operations, a practical starting point is the workflow where the data is cleanest, the exception path is already understood, and the service impact can be measured without risking the guest relationship.
For many hotels, that means manual reservation follow-up before full guest-facing resolution. AI data engineering can support this by drafting confirmations, summarizing booking context, suggesting next actions, and routing unusual cases to staff. Overbookings, special accommodations, cancellations, and VIP interactions should still move through human approval.
This is where AI data engineering becomes practical instead of theoretical. The workflow is simple enough to govern, but important enough to prove value.
It is also where AI data engineering gives leaders a measurable boundary: automate the repeatable work, escalate the exception, and learn from the handoff.
How to use AI without losing personal guest service
This is where discipline matters. AI should handle the repetitive layer of service, not the emotional layer. Draft, summarize, classify, retrieve, and route with AI. Escalate judgment, recovery, and exception handling to people.
That design approach aligns with risk-based prioritization in NIST’s AI Risk Management Framework and the AIRC Playbook, both of which support practical governance choices based on use case context and impact. It also fits the architectural logic in the AWS Well-Architected Framework, which treats operational excellence and reliability as design decisions, not post-launch fixes.
A hotel does not protect personal service by avoiding AI completely. It protects personal service by choosing where AI supports the experience and where a human stays in control. That is the difference between process automation that helps staff and automation that damages trust.
Custom AI Assistant or Generic Chatbot: The Integration and Memory Decision
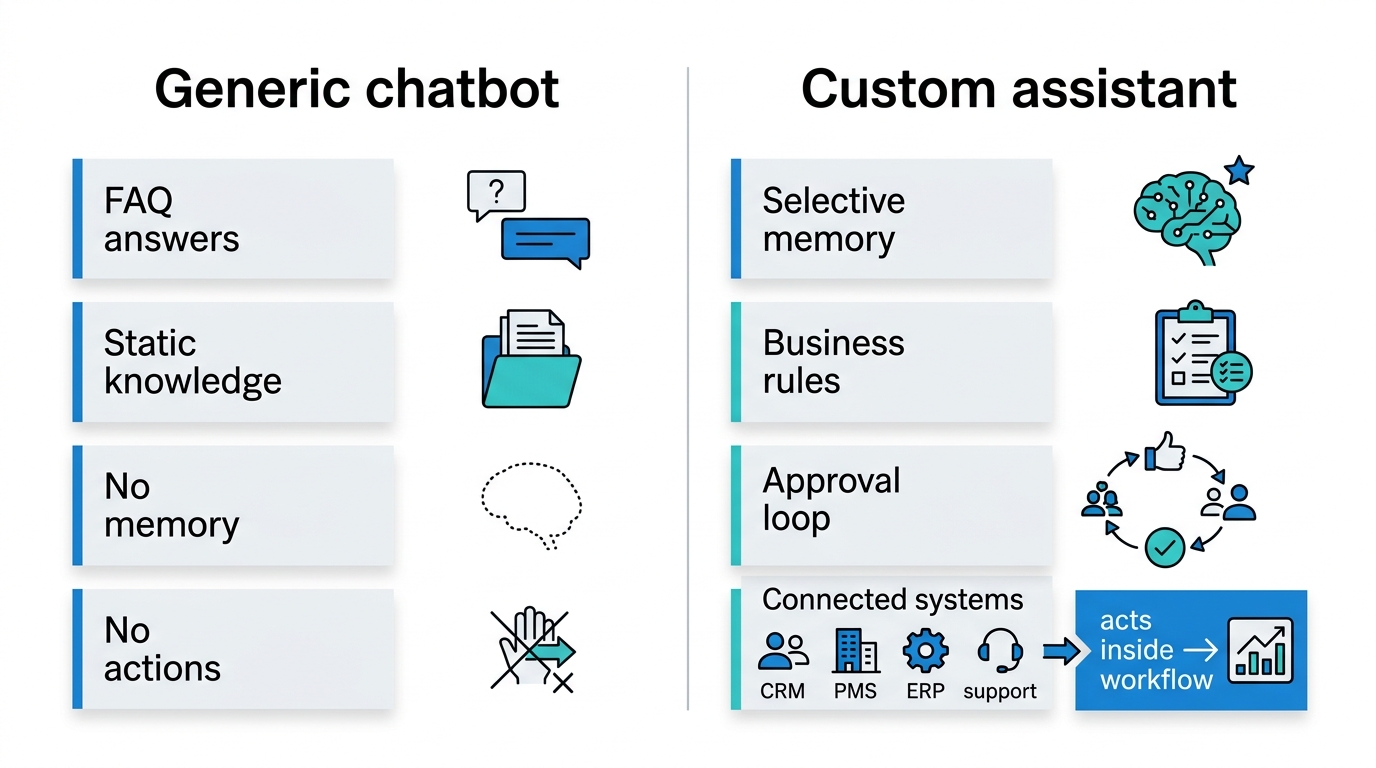
The next decision is architectural. Once you know the workflow, you have to decide what kind of AI should power it.
A generic chatbot can answer common questions. But enterprise workflows usually need more than answer generation. They need memory, connected systems, business rules, approvals, and action across tools.
When a generic chatbot is enough, and when it is not
If the use case only needs static knowledge and simple FAQs, a generic chatbot may be enough. If the use case must understand guest context, account history, unresolved issues, loyalty state, booking status, or service entitlements, a custom assistant is usually the better fit.
That is not a universal rule. It is an implementation judgment. But it reflects a simple truth: customer-facing AI becomes valuable when it works inside real workflows, not outside them. AI data engineering is what connects that assistant to the systems and records it needs.
What an AI assistant should remember
It should remember what is operationally useful and explicitly approved.
That usually means selective memory: preferences, current status, open service issues, recent interactions, approved loyalty context, and account-level facts that help the next step happen smoothly. It does not mean keeping every detail forever or exposing sensitive information just because the system can access it.
How to make AI memory safe for enterprise workflows
Safe AI memory starts with boundaries. Define what can be stored, where it can be reused, who can access it, how long it lives, and which updates require human approval. Memory should be governed like any other business data asset.
Security guidance from the OWASP Top 10 for LLM Applications and the OWASP GenAI Security Project archive is useful here because it highlights risks around sensitive data exposure, prompt injection, and insecure tool use in LLM-based systems.
How AI connects with Salesforce, CRM, PMS, ERP, and support systems
This is where AI data engineering becomes systems engineering. AI should not become another disconnected layer. It should sit on top of trusted integration patterns and authoritative records.
Salesforce integration patterns guidance describes common approaches for request-reply, data synchronization, event handling, and process integration. Salesforce Help for Data Cloud also shows how customer data can be unified across connected environments. If your AI must sit inside CRM workflows, our salesforce development team can design the integration layer that keeps records, routing, and approvals aligned. AI only works when PMS, support, finance, and CRM ERP systems can share trusted context through clear ownership and integration rules.
That is why the custom assistant versus generic chatbot decision is really an integration and governance decision. The more action the AI needs to take, the more your architecture matters. AI data engineering gives that architecture its reliability.
How to Control AI Cost Before Scaling It Across the Enterprise
Cost control should not begin after launch. It should begin in the design phase.
When leaders ask how to control LLM and AI agent costs before scaling, the answer is usually not procurement alone. It is architecture. Prompt size, retrieval quality, model choice, retry logic, tool-call frequency, context management, and escalation rules all affect cost.
What finance and technology leaders should measure
A practical scorecard includes:
- tokens per task
- retry rate
- tool-call frequency
- escalation rate to humans
- approval rate
- task completion rate
- cost per resolved workflow
- cost per successful handoff
These are not universal benchmarks. They are a starting framework for finance and technology leaders to evaluate whether the system is becoming more efficient or simply more active.
How to reduce token usage, retries, and tool-call costs
The hidden cost is rarely just the model. It is the chain around the model.
Shorter prompts, cleaner retrieval, fewer unnecessary model hops, better task scoping, selective memory, and stronger failure handling can all reduce cost. So can using rules for simple decisions instead of sending every interaction to a large model.
This architecture-first view fits the AWS Well-Architected Framework, which treats cost optimization, operational excellence, and reliability as core design pillars. Governance over data access and usage accountability also matters, as reflected in Microsoft Fabric governance documentation. Teams that want a clearer view of workflow performance can look at our implementation of salesforce einstein analytics and customization work to see how operational data can support better decisions. In a similar way, our customization of salesforce accounting software to optimized version case study shows how reporting logic and process alignment need to stay connected when business workflows get more complex. AI data engineering helps keep those layers from drifting apart.
If you cannot explain why an AI interaction costs what it costs, you are not ready to scale it.
How to Prove ROI From AI Before a Large Rollout
The right AI business case is rarely, “Let us transform everything.” It is, “Let us improve one workflow in a way the business can verify.”
That is why ROI should be proven at the workflow level first. Did manual reservation follow-up become faster and more consistent? Did manual service case routing improve without increasing risk? Did slow customer support escalation decrease because the right context reached the right team sooner? Did duplicate customer records and poor visibility across sales and service teams stop distorting the outcome?
Prove the change on one process before expanding
Start with a narrow process and measure before and after. Look at rework, routing accuracy, service quality, response time, approval burden, reporting confidence, and exception volume. For hospitality data and customer experience workflows, quality matters as much as speed.
A leadership team should also ask whether the AI program improved trust in the operating system itself. If the pilot forced better ownership, cleaner CRM data integration, and more reliable dashboards, that is part of the return. AI data governance is not overhead. It is part of the value creation.
This is where governance frameworks matter again. NIST’s AI Risk Management Framework, the NIST AI RMF Playbook, and ISO/IEC 42001 all reinforce that accountable AI needs structured oversight and management discipline. When secure application design is part of the ROI discussion, the OWASP Top 10 for LLM Applications and the OWASP GenAI Security Project archive are useful reminders that unsafe AI can create new costs even when the pilot looks productive. AI data engineering is what makes that accountability operational.
For teams that need help turning this readiness framework into an execution plan, AI consulting services can define the data, workflow, and governance sequence before rollout. Once that foundation is proven, Generative AI services and solutions can extend the pattern into assistants, copilots, search, and workflow automation that the business can actually trust.
The Practical Enterprise AI Readiness Question That Comes Before Automation
The real question is not whether AI can automate a workflow. The real question is whether your business has earned the right to automate it.
That means fixing data quality, clarifying data ownership, choosing one workflow with a limited blast radius, defining human approval, connecting systems cleanly, and measuring cost and ROI before expanding. It means treating AI readiness as a deliberate operating model, not a rushed feature launch. It also means understanding that AI data engineering is only valuable when it connects trusted records to a real business decision.
At Webuters Technologies, this is how we think about enterprise AI: not as a chatbot project, but as a business system that depends on trust, integration, and measurable workflow improvement. The smart next step is not to ask what AI can do in theory. It is to map which process is truly ready in practice, then shape the AI data engineering around that process. Done right, AI data engineering gives leaders a way to scale judgment without scaling confusion. The best AI data engineering programs start with that discipline and expand only when the data, process, and ownership can support the next workflow.
If you want to assess that readiness before you automate, start there. The enterprises that win with AI will not be the ones that launched first. They will be the ones that built something people could trust.
If your team is evaluating AI automation, start with a readiness review of your data, workflow ownership, integrations, and trust controls. Webuters Technologies can help map the first workflow that is safe, useful, and measurable before you scale. That is the real job of AI data engineering, and it is the difference between automation that adds leverage and automation that multiplies confusion.

Loading...