
AI agents in 2026 can feel like standing in a crowded airport terminal where every screen seems to show a different departure time. One week, a new framework promises autonomy. The next, a protocol becomes the center of gravity. Then another demo appears and makes your roadmap look old before lunch.
That is the surface problem. The real problem is harder: leaders are being asked to make product, architecture, and investment decisions while the language around AI agents keeps shifting faster than the business case. Founders, CTOs, and product teams do not need another departure board. They need a flight plan.
In practice, the durable advantage will come less from chasing every launch and more from learning the engineering primitives that compound, building narrow outcome-driven workflows around one real use case, and investing in the boring infrastructure that makes those systems reliable, observable, and secure. If you are evaluating the category as a serious business capability rather than a demo category, the question is not whether it is real. The question is whether your system can survive contact with a real workflow.
This article is a practical filter for signal versus noise in AI agents. We will cover what to learn deeply, what to build first, where the orchestrator-subagent pattern actually helps, why evals and a small set of curated test cases matter, how to think about MCP integration, and what to skip until production proves it deserves your time.
Why signal matters more than framework loyalty?
The temptation in a fast-moving category is to look for a fixed roadmap. But with AI agents, framework loyalty ages badly. Tools change, model behavior changes, protocols evolve, and the surface layer of the ecosystem gets refreshed constantly. What lasts is not your attachment to a vendor wrapper. What lasts is whether your team understands the system underneath.
That is why signal versus noise in AI agents matters so much. Noise is weekly launches, benchmark screenshots, and architecture diagrams that look impressive before they touch a real workflow. Signal is simpler: does the system solve a bounded task, can you inspect how it behaved, can you improve it without rewriting everything, and can you trust it with business actions?
The contrarian move is to value boring infrastructure over agent theater. Production systems do not become strategic because they look autonomous in a demo. They become strategic when they are measurable, governable, and dependable inside an operating process.
In AI agents, the edge in 2026 is unlikely to come from autonomy theater. It will come from building the most dependable system first.
That is why this article is not anti-framework and not anti-multi-agent. It is pro-proof. Durable primitives over weekly launches is not a conservative stance. It is the fastest way to build something that still works after the hype cycle moves on.
Learn the primitives that survive model and framework changes
If you only learn one thing deeply this year, make it the durable engineering primitives behind AI agents. Those skills survive model swaps, orchestration changes, and tooling churn.
Context engineering matters more than prompt cleverness
Anthropic’s guide to effective context engineering for AI agents makes a simple point: performance depends heavily on what context the system receives, how that context is structured, and how it is updated throughout the workflow. In plain words, context engineering is not prompt decoration. It is the operational design of what the model can see at the moment it has to decide.
A support workflow is a good example. If the model gets a ticket history, product policy, account status, and current escalation state in a clean format, it can act far more reliably than a system that receives one large blob of text and vague instructions. The hidden cost is not bad prompting. It is bad context packaging.
Tool design decides whether the workflow is dependable
Anthropic’s guidance on writing effective tools for AI agents argues that tools should have clear contracts, narrow responsibilities, understandable descriptions, and predictable error behavior. That is why tool design for AI agents matters so much. A good tool is not just callable. It is testable.
Consider a procurement workflow. One tool that reliably looks up approved vendors is better than five overlapping tools with ambiguous names and inconsistent outputs. If the system has to guess which tool to use, you have already pushed failure into the architecture.
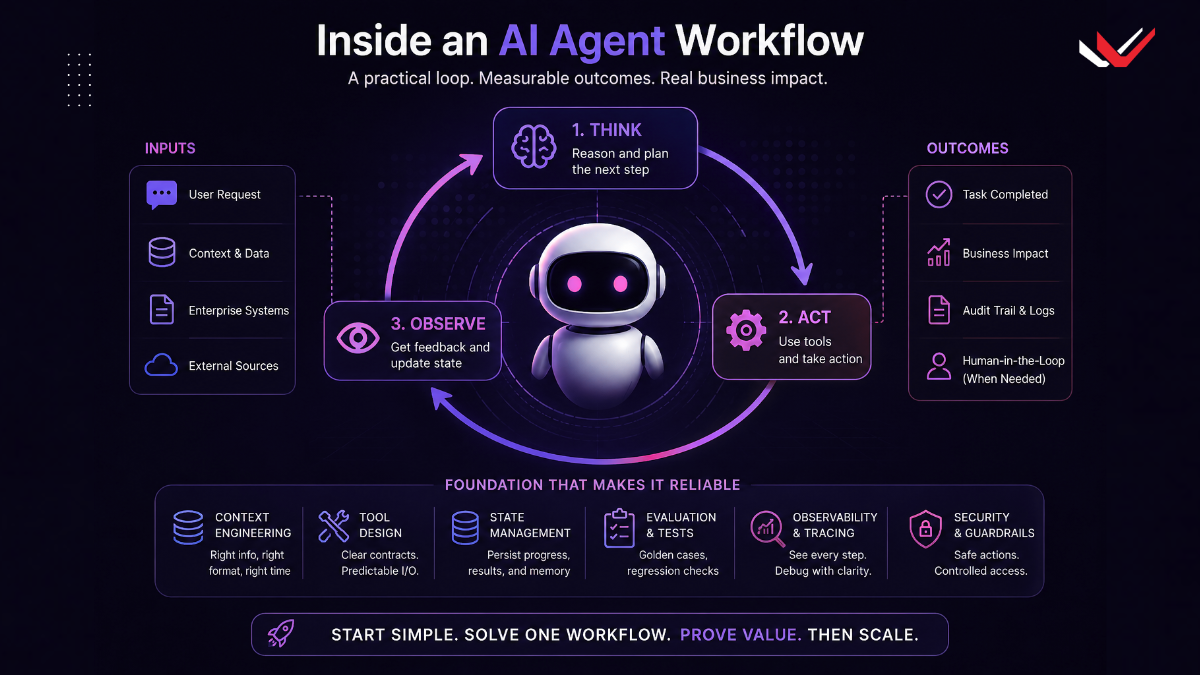
The think-act-observe loop needs visible state
The think-act-observe loop is a durable mental model for how AI agents operate. The system reasons about the next step, takes an action through a tool, observes the result, and adjusts. The loop itself does not change because the branding changes.
What makes the loop usable in production is state. A structured state store or a disciplined file system state layer gives the system somewhere to persist task progress, tool outputs, intermediate decisions, and artifacts for review. That makes the workflow inspectable in a way hidden prompt memory is not. A finance workflow that stores exception reasons, draft responses, and approval status in structured records is easier to debug than one that tries to remember everything inside the conversation.
Start with one workflow before you add complexity
The best practical advice for enterprise AI agent adoption is still this: single-agent first. Start with one system, one workflow, one owner, and one measurable outcome. That is not a limitation. It is how you keep scope tied to value.
This is where outcome-driven agents matter. Do not begin with, “What kind of autonomous assistant should we build?” Begin with, “What workflow deserves compression?” An invoice triage system that classifies exceptions, drafts a reply, and routes edge cases to a human has a clear purpose. A broad finance copilot that tries to do everything usually has unclear boundaries, unclear tools, and unclear success criteria.
Narrow agent workflows are easier to evaluate, secure, and improve. A sales operations system that updates CRM fields, summarizes meeting notes, and proposes next actions can be measured against a known workflow. A vague “revenue agent” cannot. The wider the promise, the blurrier the failure.
This is also why the build decision should be tied to fit, not novelty. The discussion around custom AI solutions vs off-the-shelf tools becomes much clearer when the workflow is explicit. If the task is narrow, high-value, and tied to your data, AI agents should be designed around that specific outcome rather than around generic autonomy.
A mini-case: one workflow, one baseline, one improvement loop
Imagine a customer onboarding team that spends too much time reading inbound documents, checking completeness, and routing missing items. The first version of the AI agents workflow does not try to automate everything. It only classifies document type, extracts a few fields, and flags missing information.
That narrow first release gives the team something useful: a baseline. Once the team can measure classification accuracy, review escalations, and inspect traces, it can decide whether the system should stay single-agent or move into a more complex design. In practice, that is how production systems earn trust. They do not start broad. They start visible.
Use multi-agent patterns only when the problem really needs decomposition
The orchestrator-subagent pattern is useful, but it is not a badge of maturity. Anthropic’s write-up on its multi-agent research system describes a lead agent coordinating subagents to parallelize parts of the research process. That is a valid design pattern when the task genuinely breaks into distinct subtasks with different success criteria.
But the caution matters just as much. Cognition’s Don’t Build Multi-Agents argues against defaulting to multi-agent systems, and its multi-agent patterns that are actually working piece shows the narrower cases where they do work. The lesson is not “never do it.” The lesson is that complexity should be earned by the problem.
A legal review workflow can justify decomposition. One subagent extracts clauses, another checks policy alignment, and an orchestrator decides whether the contract moves to human review. A support workflow that answers one escalation type probably does not need three AI agents coordinating before replying.
The goal is not to crown a winner forever. It is to choose the simplest architecture that still solves the problem.
| Approach | Best Use Case | Main Risks | Operational Complexity | Recommended Stage |
|---|---|---|---|---|
| Single-agent first | One bounded workflow with clear tools and one outcome | Overloading one system with too much scope | Low to medium | Best starting point |
| Orchestrator-subagent pattern | Problems with real decomposition, stage-specific tools, or distinct quality checks | Coordination bugs, unclear ownership, harder debugging | Medium to high | Use after a stable baseline |
| Multi-agent systems | Specialized pipelines where parallel or role-based collaboration is necessary | Fragility, latency, evaluation difficulty, security sprawl | High | Use only when evidence justifies it |
Frameworks can help express these choices, but they do not remove the architecture judgment. For example, LangGraph is positioned as an orchestration framework for stateful, long-running workflows. Useful tooling does not change the core rule: add more AI agents only when decomposition clearly improves the outcome.
Measure progress with evals, tracing, and golden datasets
The next evolution is not smarter demos. It is better feedback loops. If you want AI agents to improve over time, you need a way to tell whether they are getting better or merely sounding more confident.
Golden datasets turn opinion into evidence
A golden dataset is a set of representative tasks and expected outcomes that reflects your real workload. For a support team, that might be 50 carefully chosen escalation cases with known routing expectations, policy constraints, and acceptable response patterns. For a claims workflow, it might be a set of adjudication scenarios that reveal where the system misclassifies edge cases.
This is the operating system for evals. Without a grounded test set, every change becomes anecdotal. With it, prompt changes, tool updates, and model swaps can be tested against the same baseline.
Tracing makes reliability visible
Tracing is the difference between guessing and understanding. If a system fails, you want to know whether the failure came from bad context, the wrong tool selection, a brittle tool description, a missing permission, or a model judgment error. Observability platforms such as Langfuse support tracing and evaluation workflows for LLM applications. The principle matters more than the vendor: monitoring should show the path, not just the final answer.
This is not separate from MLOps. It is the applied version of it for AI agents. Boring infrastructure like traces, logs, versioned prompts, and test cases is what creates reliability.
Review models on a deliberate cadence
A practical starting point is quarterly review rather than constant model chasing. That does not mean ignoring new releases. It means reviewing them against your test set, latency requirements, tool-calling behavior, and cost boundaries on a deliberate cadence.
That discipline matters because the wrong model decision can look fine in a demo and still break a workflow. A regular review gives leaders a sane way to re-evaluate routing, tool behavior, and prompt structure without rebuilding the stack every week.
Treat MCP as a tool integration layer, not a strategy
The conversation around MCP integration is useful, but it needs a grounded frame. The Model Context Protocol specification defines a standard way for models and clients to connect to tools and data sources through a structured client-server pattern. The MCP introduction describes MCP as a common protocol for connecting AI applications with external systems.
That matters because interoperability is a real problem. If different AI agents need to use approved internal systems, a consistent tool integration model can reduce connector chaos. But MCP is not the strategy itself. It does not remove the need for access control, good tool descriptions, state management, evals, or auditability.
In simple words, MCP helps standardize how tools are exposed. It does not decide what the tools should do, what permissions they need, or how the workflow should fail safely. Teams that understand this tend to get more value from the protocol because they treat it as part of the stack, not as a shortcut around system design.
Put security boundaries in place before an agent can act
Once AI agents move from answering questions to taking actions, security stops being a side topic. It becomes architecture. The OWASP Top 10 for Large Language Model Applications and the OWASP GenAI risk archive outline system-level risks such as prompt injection, insecure output handling, excessive agency, and other operational threats. The NIST AI Risk Management Framework frames AI risk work around governance, mapping, measurement, and management.
This is where production guardrails matter. A finance workflow may be allowed to prepare a payment draft, but not submit it. A developer assistant may be allowed to run tests, but only in sandboxed environments. A policy workflow may read internal documents, but not access regulated systems without role-based approval. The point is not to block capability. The point is to bound blast radius.
NIST defines a sandbox as an isolated environment. That definition is useful because it turns a vague safety idea into a concrete design choice. Platforms such as E2B position sandboxed environments specifically for agent execution workloads. Whether you build or buy that layer, the principle is the same: action-taking systems need execution boundaries, permission controls, and approval paths.
The future belongs to teams that treat security as an enabler of adoption. If a system cannot be trusted to act safely, it will never become a real part of the business process.
Skip abstractions that do not reduce real pain
Not everything deserves your attention right now. In AI agents, one of the most valuable skills is deciding what to ignore.
Skip abstractions that add ceremony without reducing real pain. If a new framework makes the diagram prettier but does not improve reliability, observability, or safety, it is probably too early for your use case. Skip benchmark obsession when the benchmark does not resemble your workload. Your own test set will tell you more about business fitness than a leaderboard built for someone else’s task.
Skip autonomous-agent promises that quietly assume away approvals, recovery, governance, and audit trails. That is where production systems go to break. The gap between a compelling demo and a dependable workflow is usually not model intelligence. It is operational discipline.
And skip complexity you have not yet earned. If your first workflow still lacks traces, evals, visible state, and permission boundaries, adding more layers will only hide the real problem. This is why leaders evaluating AI agents should filter for dependable system design, not just surface capability.
FAQ: Practical questions about AI agents
What are AI agents in 2026, in practical terms?
In practical terms, AI agents are software systems that use a model to reason through a task, call tools, manage state, and take bounded actions toward an outcome. The useful distinction is not whether something is labeled an agent, but whether it can operate through a repeatable think-act-observe loop with clear tools, state, and guardrails.
Should we start with a single agent or a multi-agent system?
Start single-agent first unless the problem clearly requires decomposition. One system handling one bounded workflow is easier to evaluate, secure, trace, and improve. Move to an orchestrator-subagent pattern only when the task has separable stages, specialized tool needs, or distinct quality checks that justify the added coordination.
What is context engineering, and why does it matter so much?
Context engineering is the design of what information the system sees, when it sees it, and in what structure. According to Anthropic’s guidance, AI agents perform better when context is relevant, structured, and updated deliberately. In business terms, stronger context reduces preventable mistakes.
Where does MCP fit in an AI agent architecture?
MCP fits in the tool integration layer. It provides a standard way to expose tools and data sources to models and clients. It can reduce integration friction, but it does not replace tool design, permissions, state management, or evaluation.
How often should we review models for production AI agents?
A practical recommendation is quarterly review using golden datasets, traces, and workflow-level metrics. That cadence helps teams compare model choices without constantly rebuilding the stack around every new release. If a workflow is especially sensitive, you can review more often, but the key is to evaluate deliberately rather than chase every release.
What is the minimum infrastructure needed for production AI agents?
At minimum, production AI agents need clear tool contracts, a structured state store or file-based state layer, traces, evals, a test set, permission controls, and a safe execution boundary for risky actions. Everything else is secondary to whether the system can be observed, tested, and governed.
The practical takeaway for teams building AI agents
The winning move in AI agents in 2026 is not autonomy theater. It is building systems that can survive contact with an actual business workflow. That means learning durable engineering primitives, starting with one narrow outcome, instrumenting the system with evals and traces, using MCP integration where it genuinely reduces friction, and putting security and sandboxing in place before the system gets real authority.
The next step is simple: choose one workflow that matters, define the boundary, and prove reliability before you widen the scope. If your team is moving from experiments to production decisions, Webuters can help you turn that first workflow into a practical roadmap through AI consulting services and Generative AI Services and Solutions.

Loading...